Apache spark is a framework for distributed computing. A
typical Spark program runs parallel to many nodes in a cluster. For a detail
and excellent introduction for spark please have a look into Apache spark website
(https://spark.apache.org/documentation.html).
The
purpose of this tutorial is to walk through a simple
spark example, by setting the development environment and doing some
simple
analysis on a sample data file compose of userId, age, gender,
profession, and zip code (you can download the source and the data
file from Github https://github.com/rjilani/SimpleSparkAnalysis).
For the sake of this tutorial I will be using IntelliJ community IDE with Scala plugin; you can download the IntelliJ IDE and the plugin from IntelliJ website. You can also use your favorite editor or Scala IDE for Eclipse if you want to. A preliminary understanding of Scala as well as Spark is expected. The version of Scala used for this tutorial is 2.11.4 with Apache Spark 1.3.1.
For the sake of this tutorial I will be using IntelliJ community IDE with Scala plugin; you can download the IntelliJ IDE and the plugin from IntelliJ website. You can also use your favorite editor or Scala IDE for Eclipse if you want to. A preliminary understanding of Scala as well as Spark is expected. The version of Scala used for this tutorial is 2.11.4 with Apache Spark 1.3.1.
Once
you have installed the IntelliJ IDE and Scala plugin,
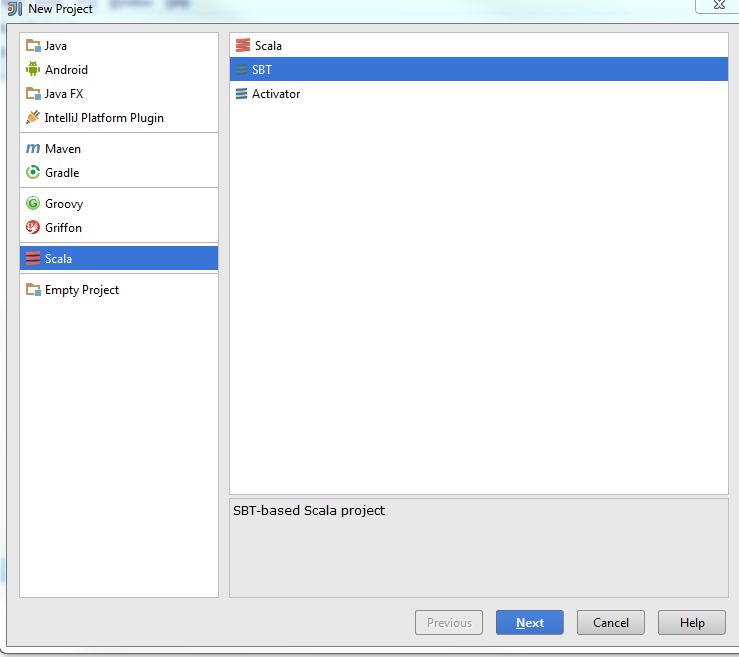
please go ahead and start a new Project using File->New->Project
wizard and then choose Scala and SBT from the New Project Window
Wizard. At this stage if
this is your first time to create a project, you may have to choose a
Java
project SDK, a Scala and SBT version.
//Data file is transformed in Array of tuples at this point
Once the project created please copy and pastes the
following lines to your SBT file
name := "SparkSimpleTest"
version := "1.0"
scalaVersion := "2.11.4"
libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "1.3.1",
"org.apache.spark" %% "spark-sql" % "1.3.1", "org.apache.spark" %% "spark-streaming" % "1.3.1")
version := "1.0"
scalaVersion := "2.11.4"
libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "1.3.1",
"org.apache.spark" %% "spark-sql" % "1.3.1", "org.apache.spark" %% "spark-streaming" % "1.3.1")
Note: you don’t need to have spark SQL and spark streaming
library to finish this tutorial, but add it any way in case you have to use
spark SQL and streaming for future examples. Once you save SBT file, IntelliJ will ask
you to refresh, and once you hit refresh it will download all the required dependencies.
Once all the dependencies are downloaded you are ready for fun stuff.
Go ahead and add a new Scala class of type Object (without
going deep into the Scala semantics, it means your class will be
executable with a main method inside it).
For sake of brevity I would also omit the boiler plate code in this
tutorial (you can download the full source file from Github https://github.com/rjilani/SimpleSparkAnalysis). Now let’s jump into the code, but before proceed
further lets cut the verbosity by turning off the spark logging
using these two lines at the beginning of the code:
Logger.getLogger("org").setLevel(Level.OFF) Logger.getLogger("akka").setLevel(Level.OFF)
Now add the following two lines:
val conf = new SparkConf().setAppName("Simple Application").setMaster("local") val sc = new SparkContext(conf)
The line above is a boiler plate code for creating a spark
context by passing the configuration information to spark context. In spark programming
model every application runs in spark context; you can think of spark context as
an entry point to interact with Spark execution engine. The configuration
object above tells Spark where to execute the spark jobs (in this case the
local machine). For a detail explanation of configuration options please refers
Spark documentation on spark website.
Spark is written in Scala, and exploit the functional programming paradigm, so writing map and reduce kind of jobs becomes very natural and intuitive. Spark exposes many transformation functions and the detail explanation of these functions can be found on spark website (https://spark.apache.org/docs/latest/programming-guide.html#transformations).
Now get back to fun stuff (real coding):
Spark is written in Scala, and exploit the functional programming paradigm, so writing map and reduce kind of jobs becomes very natural and intuitive. Spark exposes many transformation functions and the detail explanation of these functions can be found on spark website (https://spark.apache.org/docs/latest/programming-guide.html#transformations).
Now get back to fun stuff (real coding):
val data = sc.textFile("./Data/u.user") //Location of the data file .map(line => line.split(",")) .map(userRecord => (userRecord(0), userRecord(1), userRecord(2),userRecord(3),userRecord(4)))
The
code above is reading a comma delimited text file composed of user’s
records, and chaining the two transformations using the map function.
The first map function takes a closure and
split the data file in lines using a “,” delimiter. The second map
function takes each line record and
creating an RDD (resilient distributed dataset) of Scala tuples. Think
of Scala
tuples as an immutable list that can hold different type of objects.
Every spark RDD object exposes a collect method that returns
an array of object, so if you want to understand what is going on, you can iterate the whole RDD as an
array of tuples by using the code below:
data.collect().foreach(println)
//Data file is transformed in Array of tuples at this point
(1,24,M,technician,85711)
(2,53,F,other,94043)
(3,23,M,writer,32067)
………
The whole fun of using Spark is to do some analysis on Big
Data (no buzz intended). So let’s ask
some questions to do the real analysis.
1.
How many unique professions we have in the data
file
//Number of unique professions in the data file
val uniqueProfessions = data.map {case (id, age, gender, profession,zipcode) => profession}.distinct().count()
Look at the code above, that is all it takes to find the
unique professions in the whole data set, isn't it amazing. Here is the explanation of the code:
The map function is again an example of the transformation,
the parameter passed to map function is a case class (see Scala case classes)
that returns the attribute profession for the whole RDD in the data set, and then we call
the distinct and count function on the RDD .
2.
How many different users belongs to a unique professions
//Group users by profession and sort them by descending order val usersByProfession = data.map{ case (id, age, gender, profession,zipcode) => (profession, 1) } .reduceByKey(_ + _).sortBy(-_._2)
The map function is again an example of the transformation,
the parameter passed to map function is a case class (see Scala case classes)
that returns a tuple of profession and integer 1, that is further reduce by “reduceByKey”
function in unique tuples and sum of all the values related to the unique tuple.
“SortBy” function is a way to sort the RDD by passing a closure, that takes a tuple as an input and sort the RDD on the basis of second element of tuple (in our case it is the sum of all the unique values of the professions). A “-“sign in front of the closure is a way to tell “sortBy” to sort the value in descending order.
“SortBy” function is a way to sort the RDD by passing a closure, that takes a tuple as an input and sort the RDD on the basis of second element of tuple (in our case it is the sum of all the unique values of the professions). A “-“sign in front of the closure is a way to tell “sortBy” to sort the value in descending order.
You can print the list of professions and their count using the line below
usersByProfession.collect().foreach(println)
(student,196)
(other,105)
(educator,95)
(administrator,79)
...........
(student,196)
(other,105)
(educator,95)
(administrator,79)
...........
3.
How many users belongs to a unique zip code in
the sample file
//Group users by zip code and sort them by descending order val usersByZipCode = data.map{ case (id, age, gender, profession,zipcode) => (zipcode, 1) }
.reduceByKey(_ + _).sortBy(-_._2)
(55414,9)
(55105,6)
(55337,5)
(20009,5)
(10003,5)
(55454,4)
........................
4.
How many users are male and Female
//Group users by Gender and sort them by descending order val usersByGender = data.map{ case (id, age, gender, profession,zipcode) => (gender, 1) } .reduceByKey(_ + _).sortBy(-_._2)
(M,670)
(F,273)
The item 3 and 4 uses the
same pattern as item 2, the only difference is that map functions
returns the tuple of zip code and gender that is further reduce by
"reduceByKey" function.
I hope the above tutorial is easy to digest, if not please hang in there, brush up you Scala skills and then review the code again, Hope with the time and practice you will find the code much easier to understand.
I hope the above tutorial is easy to digest, if not please hang in there, brush up you Scala skills and then review the code again, Hope with the time and practice you will find the code much easier to understand.